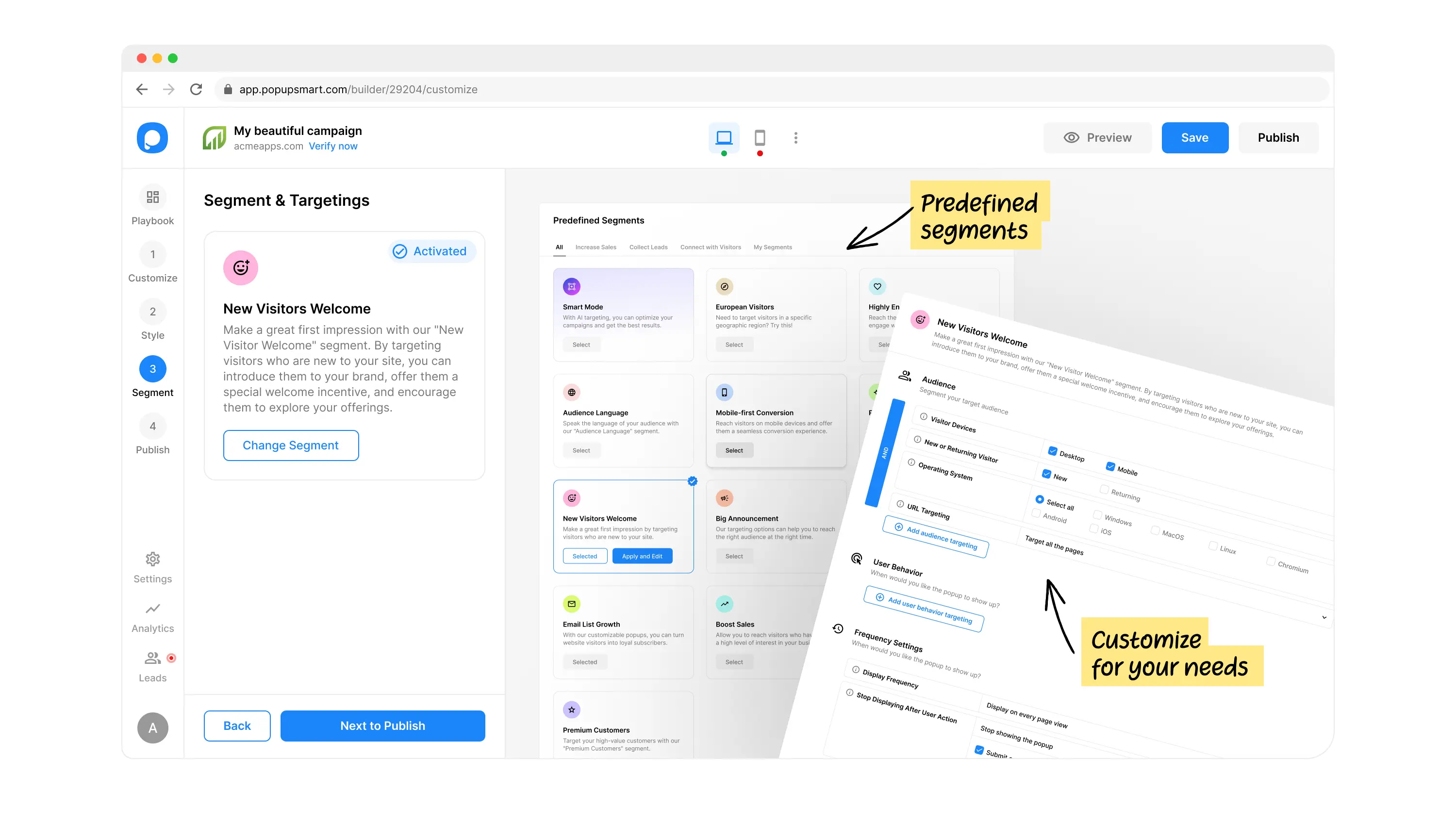
Increase Sales
Increase Sales Conversion
Can’t turn your site traffic into sales?
Reduce Cart Abandonment
Your customers abandoning their carts?
Promote Products & Offers
Make potential customers notice special offers.
COLLECT LEADS
Collect Form Submission
Struggling to collect form submissions?
Get More Phone Calls
Let them call you directly via popups.
Grow Email List
Having trouble growing your email list?
Gamify Your Campaign
Choose your offer and let the game begin.
CONNECT WITH VISITORS
Make Announcement
Make sure important news unmissed.
Increase User Engagement
Keep visitors & customers on your site longer.
Collect Feedback & Surveys
Can’t draw attention to your surveys?
Facilitate Social Sharing
Grow social media followers and likes!



Free and paid plans
Setup in minutes
No credit card required
Start your free trialSign in with your
Popup builder that boosts sales.
A no-code tool to increase e-commerce sales, build email lists, and
engage with your visitors in just 5 minutes.
Get started now,
no account is required.
Free and paid plans Setup in minutes No credit card required
3.000+ clients are getting higher conversion rates
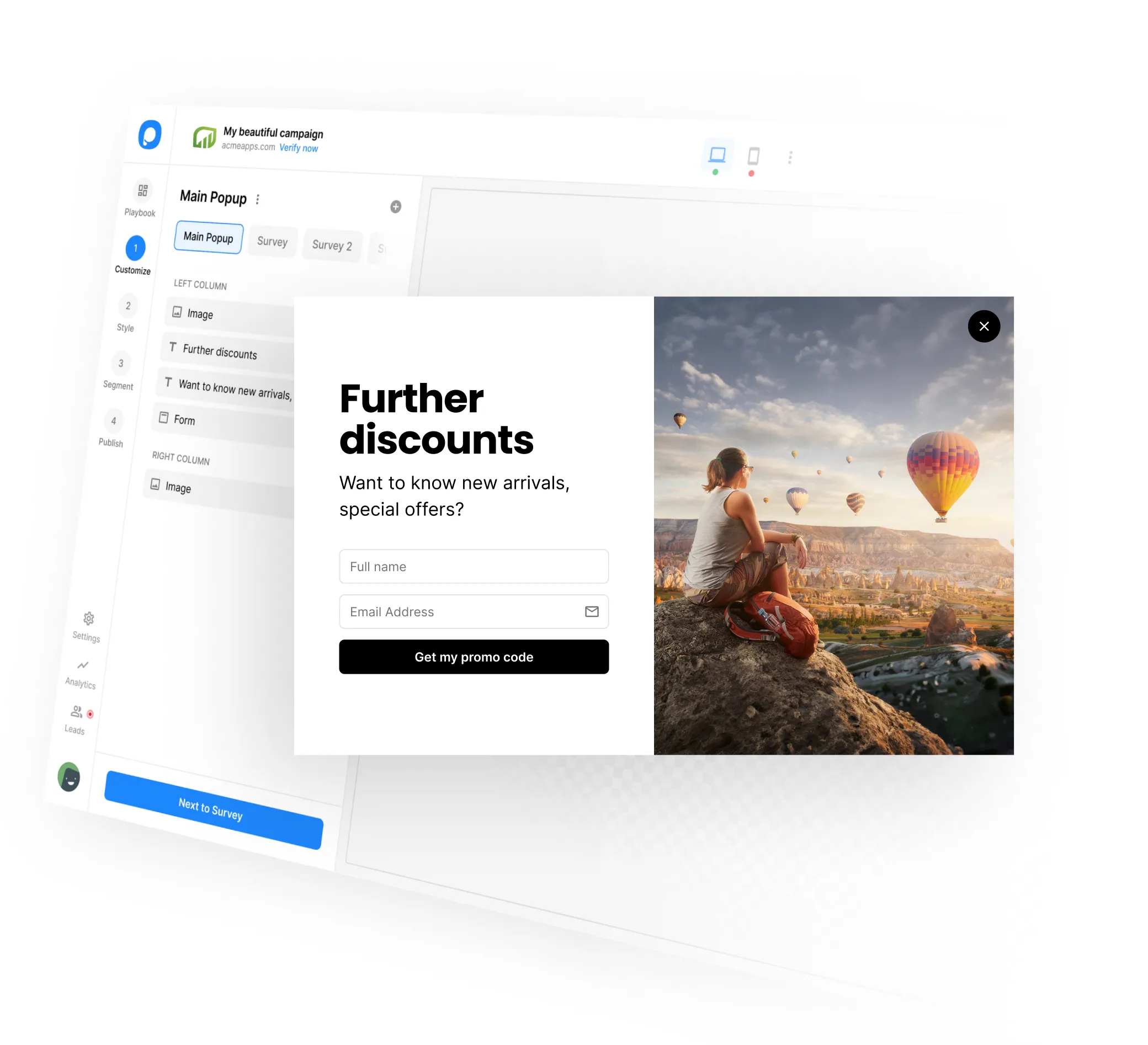
How it works
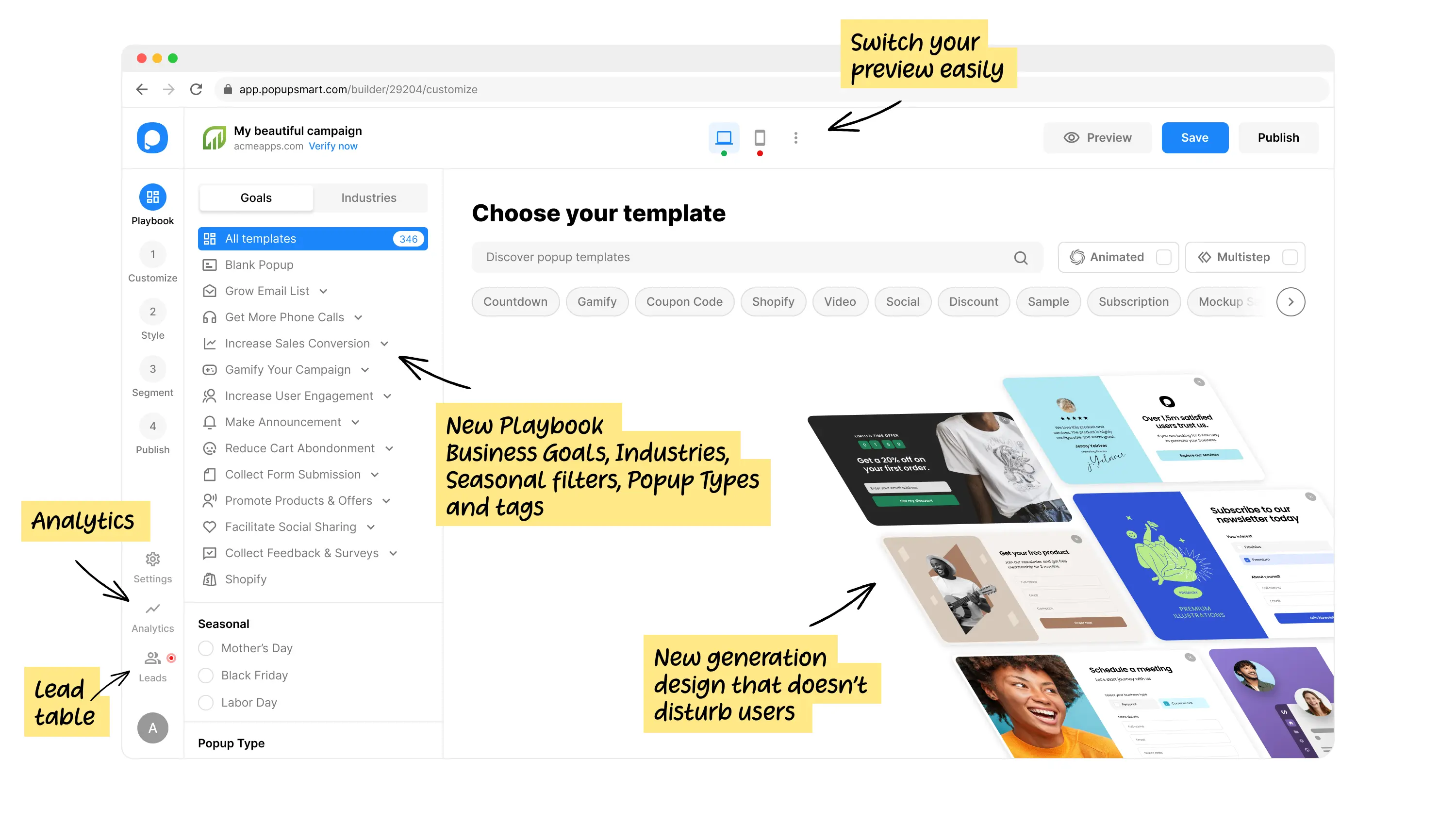
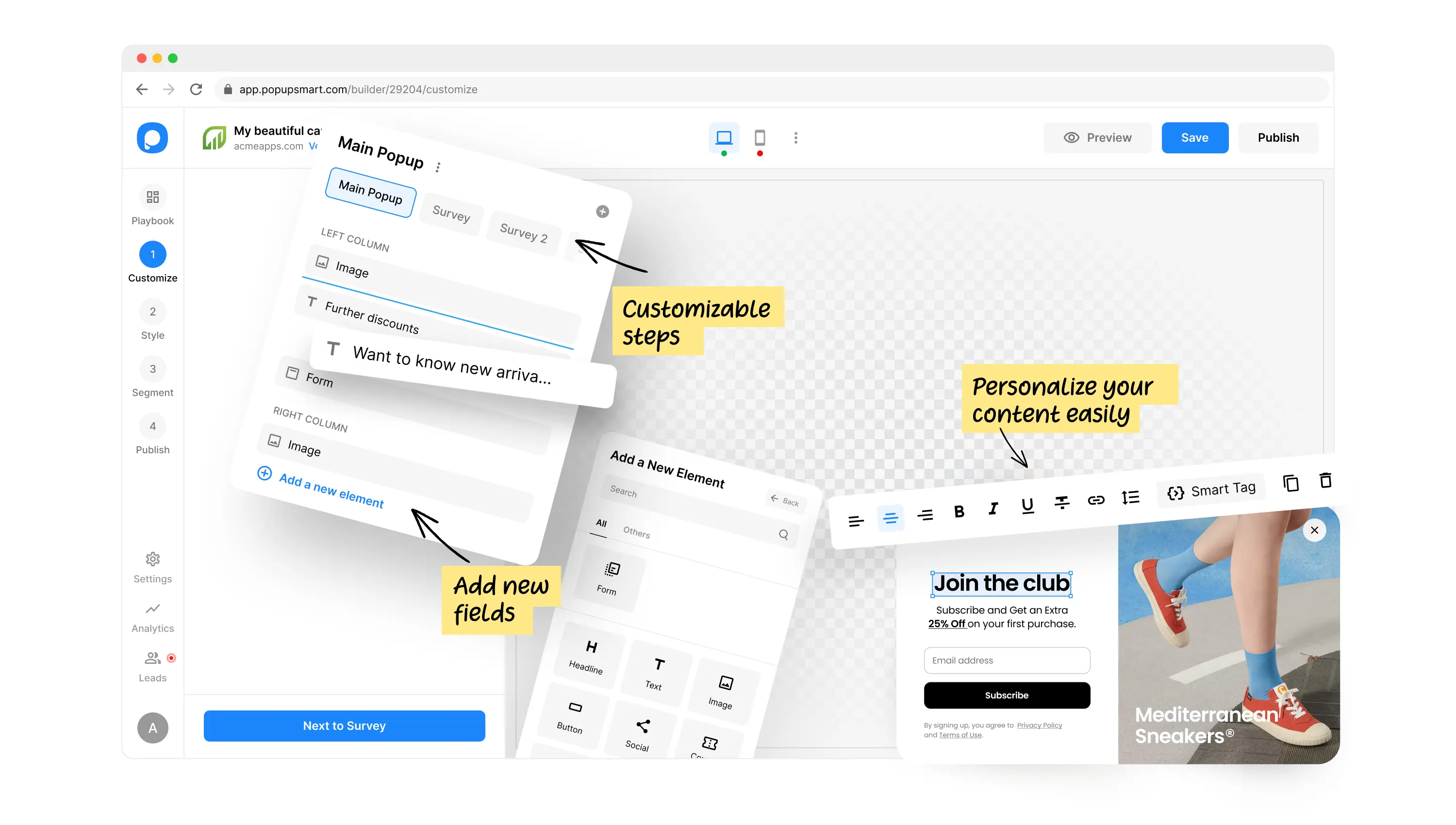
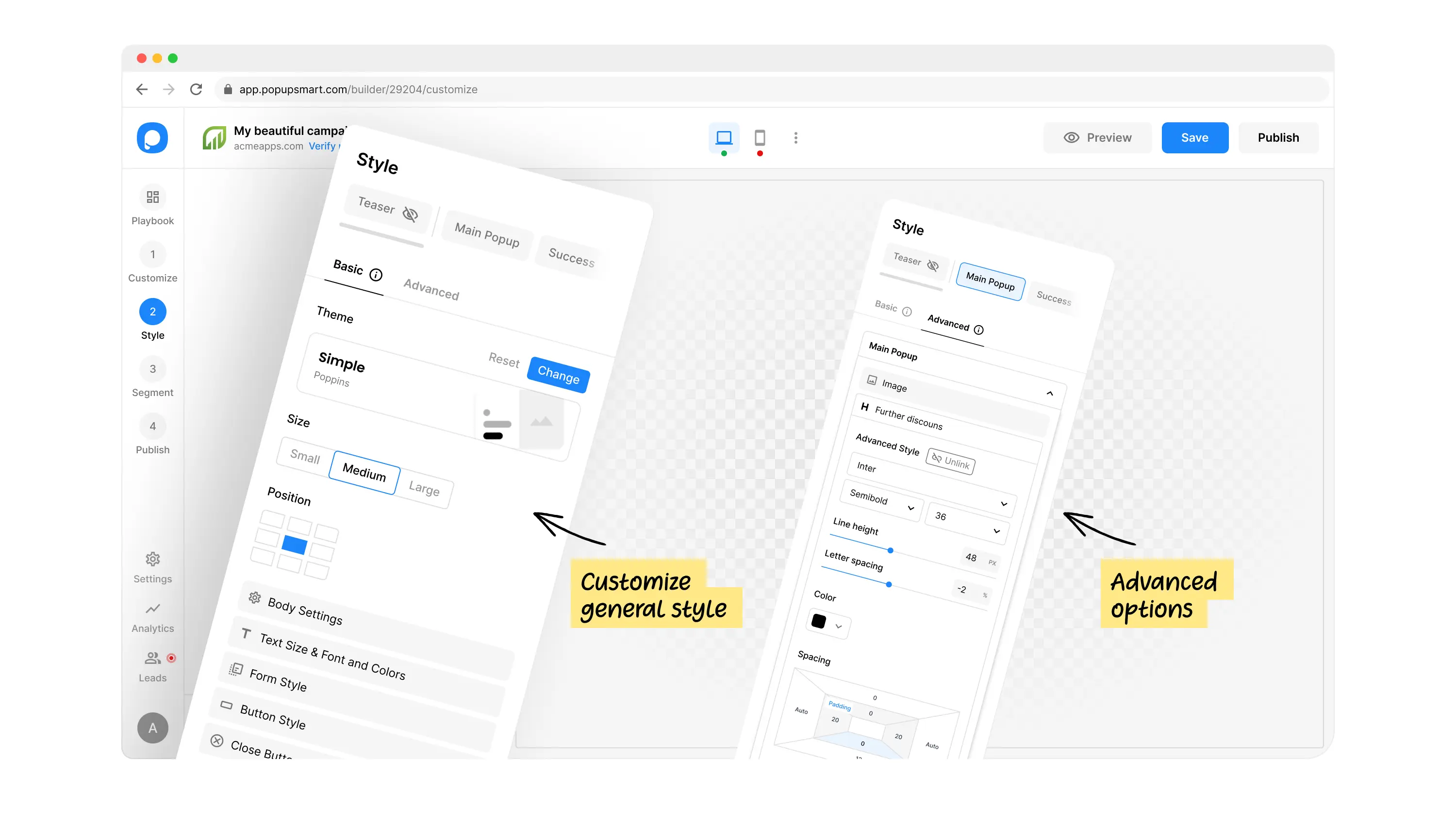

SALES
Increase Sales Conversion

PROMOTE
Promote Products & Offers

CART
Reduce Cart Abondonment

FEEDBACK
Collect Feedback & Survey

PHONE
Get More Phone Calls

GROW
Grow Your Email List

GAMIFY
Gamify Your Campaign

ANNOUNCEMENT
Make Announcements

ENGAGEMENT
Increase User Engagement

FORMS
Collect Form Submissions

SOCIAL
Facilitate Social Sharing
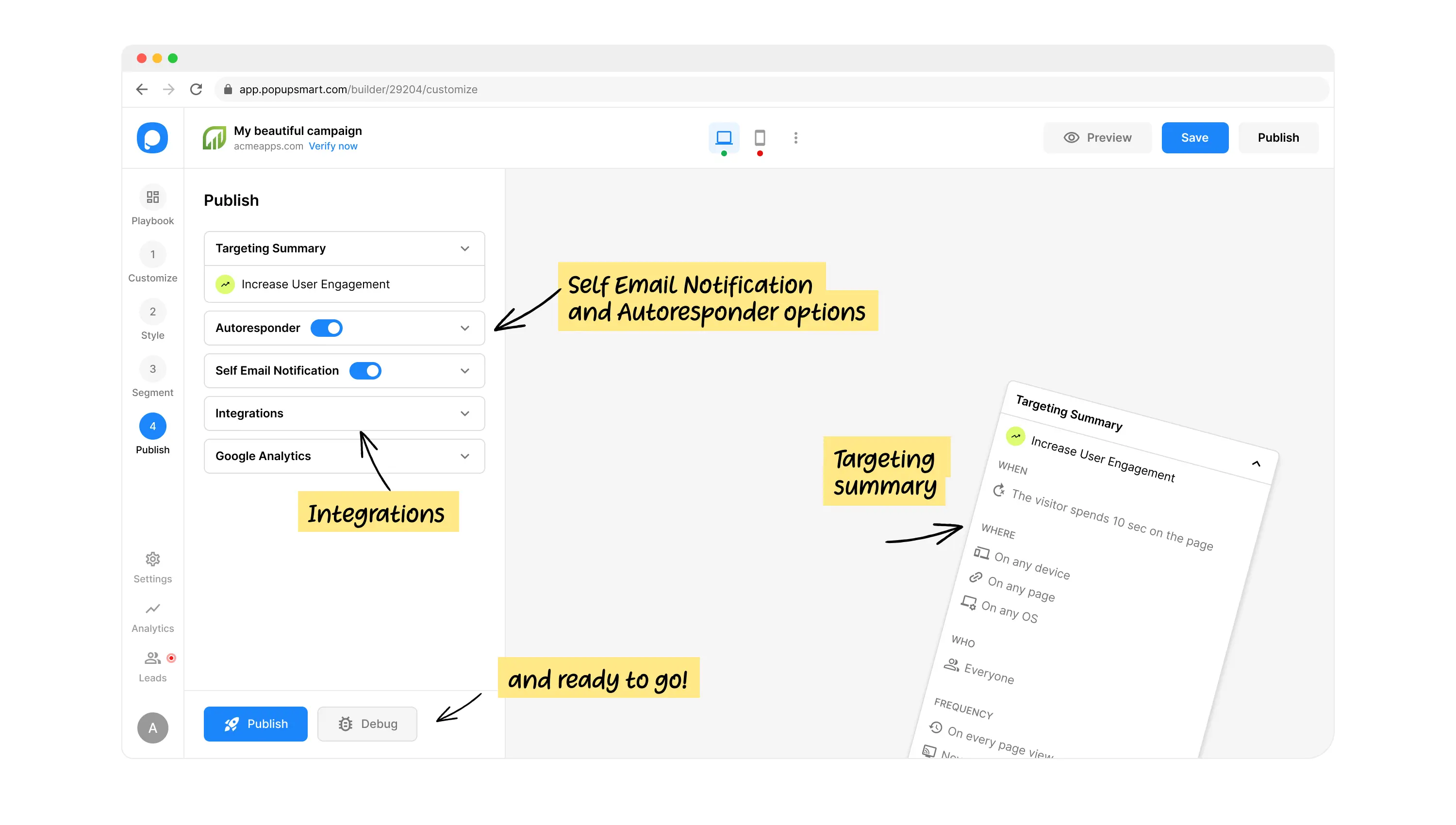
Flawless integrations
with your favorite tools
Effortlessly connect your Popupsmart account with your
preferred service provider to maximize website conversions.
See all tools 
and more than 120+ tools to integrate
Recipes that increase sales.
Popular ways to start growing today.

Collect Emails 4X Faster with Popupsmart VS. Mailchimp Popup

Receive Feedback on Thank You Page with a Form Popup

Create a ‘Frequently Bought Together’ Popup to Skyrocket Sales
Companies grow for the better when they work with Popupsmart.
Reviewed more than 250+
“Easy set-up without coding. I love the possibility with the existing templates which you can adapt.”
- Kris S, Marketing Manager
“Before using Popupsmart, we used Mailchimp’s popups to capture emails in our blog. The problem with Mailchimp was that their embed code was slowing down our website and customization was limited. Since we’ve started to use Popupsmart, our conversion rate has increased around 40% and our website is loading much faster!”
- Mert Aktas, Growth Manager
“It was great, especially for the targeting part. We have created numerous setups according to traffic sources and triggered those popups while user engagement is high enough to increase our CTRs / fill rates.”
- Yigit Konur, Passionate Founder
“Overall, I’ve had a great experience with Popupsmart. Great enough to take time to convince my marketing department that we should use this service among the others we’ve tested. Our current customers and the clear analytics on the dashboard (as well as in our CRM) show that we made the correct decision.”
- Victor W, Graphic Designer
Customer Stories
See our customers' journeys to success.


DorukNet's Journey to Increased Leads & Lowered Exit Rates with Popupsmart
Read Case Study
Flatart's Conversion Success: How Popupsmart Amplifies Customer Satisfaction
Read Case StudyFrequently Asked Questions
Can’t find what you are looking for?
We would like to chat with you.
-
Popupsmart is a potent conversion optimization tool; therefore, it is suitable for marketing agencies, bloggers, e-commerce websites, and all medium-scale and smallscale companies.
Let me explain it differently. If your business goals include growing email list, increasing phone calls, designing a website that is compliant with cookie laws, collecting form submissions, promoting your products, and showing up notifications, you definitely need Popupsmart’s conversion-driven popups on your website. -
You are not required anything to use Popupsmart. It is a no-code tool. All you need to do is to create a free account, design a popup or select one of our predesigned popup templates, and embed the popup code to your website.
Popupsmart can be installed on every website platform on the internet. Moreover, we offer integrations with the most powerful digital solution providers. -
No, you don’t need to have any coding skills to have great popups on your website via Popupsmart. You may create your popup via Popupsmart’s Smart Editor, and the only requirement including a code is to paste the embed code to your website’s source code that you obtain at the end of the editing process.
-
No, you don’t need to have design skills to design stunning popups with Popupsmart. We offer more than 35 free popup templates that alter according to your selected business objective. You can choose one template and customize it as you wish. There will also be some design limits and recommendations for you to build conversion-driven popup designs.
-
You should choose to work with Popupsmart over similar popup apps because our popup service is the most cost-effective one. We offer 7/24 free live chat opportunity. Also, our advanced features are great for driving conversions to your website. You can explore our popup comparison page to be sure about your choice.
-
Perfect designs - easy to customize popup designs, no coding knowledge required, fully responsive popup designs, browser compliant popups, GDPR-ready popup templates.
Advanced targeting options - exit-intent triggers, scroll triggers, geo-located targeting, in-activity censor, traffic source targeting, device-based targeting, remarketing opportunity.
Flawless integration opportunities - Zapier and Popupsmart integration, MailerLite and Popupsmart integration, MailChimp and Popupsmart integration, webhook configuration.
Actionable insights - Instant event and goal tracking, real-time engagement statistics. -
Our success team would love to assist you with getting Popupsmart setup on your website. We are also aware that setup process may be confusing; therefore, we offer free help for building your first popup campaign and embedding it to your website.
Additionally, our digital specialists would like to help you in every matter of obtaining success in digital. Do not hesitate to communicate with us via live chat on 24/7! -
Yes, Popupsmart offers annual payment plans, but you cannot purchase a yearly redemption plan from the popup app. If you demand to have an annual agreement, contact us via live chat to start our partnership for your organization’s conversion with up to 30% discount.
Load more questions
Our support heroes are here for you 24/7
Effortlessly connect your Popupsmart account with your preferred service provider to maximize website conversions.

The Only Popup Builder You Need
Popupsmart meets all your business needs and everything you would look for in a popup builder. Converting targeting and trigger features help you to build personalized popup and email automation campaigns. Thanks to popup building and email automation templates, you don’t have to worry about designing a popup and email campaign from scratch. We got you covered with industry-leading design features and customization options. As a result, you can enjoy your conversion-ready popups and automated emails to save time, money, and effort.
Intuitive and Incredibly Simple to Use
Popupsmart has an intuitive and easy-to-use user interface since it is a no-code popup builder. Our main aim is to provide you with a popup maker and email automation with a low learning curve. There is no need to deal with extensive coding and development. People with no-coding experience can easily create their popups and email automation campaigns in under 5 minutes! Anyone can build a remarkable popup and automated email campaign and increase conversions. You can become a professional popup creator with popup builder tutorials and comprehensive help documentation. Benefit from popup maker targeting features and reach your visitors efficiently!
One Popup Builder For All Websites
Most popup builder plugins and tools work only on limited platforms. Therefore, these might not integrate with other platforms seamlessly, and some hardships might occur. On the contrary, Popupsmart is compatible with any website that can come to your mind. Whether you own a WordPress or Squarespace website and a Shopify or WooCommerce store, it is easy to create a compatible popup. In addition, our popup builder is compatible with websites that support JavaScript so that you can copy and paste a single-line code snippet to your website’s code injection part. You don’t need to install any apps or write codes from scratch. By adding your unique code to your domain, you can start using popups on blogs, e-commerce websites, or any website!